

イントロダクション
前回の記事では、Pythonのプログラム上でChatGPTを呼び出す方法を学びました。
前回の記事はこちら

その際、最終的に作り上げたコードは、以下のようなコードでした。
#%%
import os # os情報の読み込み
from openai import OpenAI
OpenAI.api_key = os.environ.get("OPENAI_API_KEY") # APIキーの呼び出し
client = OpenAI()
completion = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "あなたは、コテコテの関西弁を操る10代女性です。"},
{"role": "user", "content": "今日は、日本では何の日と定められていますか?"}
]
)
print(completion.choices[0].message.content)今回は、GPT用のコードで、どのようなパラメーターが設定できるのかを紹介します。
辞書的な利用を想定しています。
わからないパラメーターがあるたびに参照するイメージでご活用ください。
ChatGPT APIで設定可能なパラメーター
上記コード上で、GPTに細かい指示を出している部分は、以下の部分になります。
completion = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "あなたは、コテコテの関西弁を操る10代女性です。"},
{"role": "user", "content": "今日は、日本では何の日と定められていますか?"}
]
)現時点で、この部分では、「model」と、「messages」というパラメータが設定されています。
以下は、この部分に設定できるパラメーターの一覧表です。
| パラメータ | 型 | デフォルトの値 |
|---|---|---|
| model | 文字列 | なし |
| messages | 辞書 | なし |
| temperarure | float | 1.0 |
| top_p | float | 1.0 |
| n | 整数 | 1 |
| stream | ブール | false |
| stop | リスト | null |
| max_tokens | 整数 | 4096 or 8192 |
| presence_penalty | float | 0.0 |
| frequency_penalty | float | 0.0 |
| logit_bias | 辞書 | null |
| user | 文字列 | なし |
項目ごとに、使い方も含めて細かい解説を行っていきます。
パラメーター1 model
前回作成したコードでは、このmodelの部分で、”gpt-3.5-turbo”を指定しました。
ここで使いたいmodelを選択することで、より高性能だったり、用途に合ったAIを指定することが出来ます。
OpenAIが提供しているモデルは、OpenAIのプラットフォームで参照することが出来ますので、詳細はこちらをご覧ください。
以下では、代表的なものを紹介しています。
| model | 説明 | 用途 | 料金(1Kトークン) |
|---|---|---|---|
| gpt-3.5-turbo | gpt-3.5-turbo-0125版 安い。3.5で済むなら。 | 自然言語 | 0.0010$/0.0020$ 入力/出力 |
| gpt-4 | gpt-4-0613版 料金が高い。 gpt-4o推奨。 | 自然言語 | 0.03$/0.06$ 入力/出力 |
| gpt-4-0125-preview | turbo最新版 | 自然言語 | 0.01$/0.03$ 入力/出力 |
| gpt-4-turbo-preview | 常に4-turbo最新版を指定。 | 自然言語 | 0.01$/0.03$ 入力/出力 |
| gpt-4o | 新規に追加された高性能で安価なモデル。 GPT-4を使うならばこちらを推奨。 | 自然言語 | 0.005$/0.015$ 入力/出力 |
| gpt-4o-2024-05-13 | 新規に追加された高性能で安価なモデル。 GPT-4を使うならばこちらを推奨。 | 自然言語 | 0.005$/0.015$ 入力/出力 |
| dall-e-3 | ひな形が異なる。 詳細はこちら | 画像生成 | $0.04~$0.120 高額/注意 |
| tts-1 | ひな形が異なる。 詳細はこちら | 読み上げ | $0.015 |
| tts-1-hd | ひな形が異なる。 詳細はこちら | 読み上げ | $0.030 |
| whisper-1 | ひな形が異なる。 詳細はこちら | 字起こし | $0.006 / 分 |
パラメーター2 messages
前回の記事では、”role”:”system”と”role”:”user”を設定し、”content”で指示を指定しました。
| role | 機能 | 記載方法 |
|---|---|---|
| system | GPTの性格・性質を改造 | {“role”:”system”,”content”:”性格”} |
| user | 利用者。質問設定。 | {“role”:”user”,”content”:”質問内容”} |
| assistant | 過去の応答や前提知識の設定。 | {“role”:”assistant”,”content”:”前提知識等”} |
roleには”role”:”assistant”という項目もあります。
“role”:”assistant”の説明は「AIの過去の応答を教える項目」と解説されていることが多いです。
いまいち直感的に理解できないところです。
基本的には「GPTに前提知識を刷り込むためのパラメーター」と解釈していいかと思います。
パラメーター3 temperature
temperatureは、GPTが生成する文章の創造性を左右するパラメーターです。
フロート(浮動小数点)で設定します。
0.0に近いほど安定性が高く、1.0を超えると生成内容に確率的な変化が発生しやすくなっていきます。
1.5を超えてくると意味を持つ文章を生成することが難しくなる場合があるようです。
創造性を重視して数値を大きくすると、文章が破綻します。
注意しましょう。
[0.8 , 0.9 , 1.0 , 1.1 , 1.2 ]のようなリストからランダムチョイスするプログラムだといい感じに働くかもしれません。
completion = client.chat.completions.create(
model="gpt-3.5-turbo",
temparature = 1.2,
messages=[
{"role": "system", "content": "あなたは、コテコテの関西弁を操る10代女性です。"},
{"role": "user", "content": "今日は、日本では何の日と定められていますか?"}
]
)パラメーター4 top_p
temparatureと同じような役割のパラメーターです。
top_p = 0 に設定すると、同じ質問に対していつも同じ回答を生成します。
top_p = 1 に設定すると、回答に毎回変化が発生します。
設定数値は、フロート(浮動小数点)で、0.7から0.95の間に調整するのが一般的なようです。
temparatureとtop_pを同時に使うことは推奨されていないと入門書には書かれています。
しかし、temparatureを上げることによる文章崩壊を、top_pを下げて回避することも可能なようです。
completion = client.chat.completions.create(
model="gpt-3.5-turbo",
top_p = 1,
messages=[
{"role": "system", "content": "あなたは、コテコテの関西弁を操る10代女性です。"},
{"role": "user", "content": "今日は、日本では何の日と定められていますか?"}
]
)パラメーター5 n
1つの質問に対して、GPTが生成する回答の数を指定するパラメーターです。
n = 2 なら一つの質問に対して2つの回答を生成し、n = 3 なら3つの回答を生成します。
当然、利用するトークンが多くなりますので、数値を上げると利用料金もn倍に跳ね上がります。
completion = client.chat.completions.create(
model="gpt-3.5-turbo",
n=2,
messages=[
{"role": "system", "content": "あなたは、コテコテの関西弁を操る10代女性です。"},
{"role": "user", "content": "今日は、日本では何の日と定められていますか?"}
]
)パラメーター6 stream
ChatGPTの回答作成の過程をリアルタイム(ストリーミング)で見るか、完成したものを見るかを決めるパラメーターです。
設定値は、「true」,「false」のブール型になります。
completion = client.chat.completions.create(
model="gpt-3.5-turbo",
stream = true,
messages=[
{"role": "system", "content": "あなたは、コテコテの関西弁を操る10代女性です。"},
{"role": "user", "content": "今日は、日本では何の日と定められていますか?"}
]
)パラメーター7 stop
GPTの使用禁止語句を設定するパラメーターです。
リスト型で記述します。
センシティブな単語や、忌避したい単語などを前もって設定します。
「”\n”」改行を禁止して回答行数を1行に制限したり、「”###”」を自分の質問の冒頭に記述したうえで、stop=[“###”]と設定し、質問のオウム返しによるトークンの無駄遣いを減らすテクニックがあります。
completion = client.chat.completions.create(
model="gpt-3.5-turbo",
stop = ["\n","###"],
messages=[
{"role": "system", "content": "あなたは、コテコテの関西弁を操る10代女性です。"},
{"role": "user", "content": "今日は、日本では何の日と定められていますか?"}
]
)パラメーター8 max_tokens
回答に消費される最大トークン数を制限できます。
モデルによって上限値が異なるようですが、最大値に設定しても回答が冗長になるだけでいいことはありません。
想定される質問やサービスに応じた適切なトークン数を設定するべきです。
また、トークン数≒文字数なのですが、特に日本語ではカウント方法が異なります。
OpenAI公式にトークン数を計測するサイトがあります。

completion = client.chat.completions.create(
model="gpt-3.5-turbo",
max_tokens = 500,
messages=[
{"role": "system", "content": "あなたは、コテコテの関西弁を操る10代女性です。"},
{"role": "user", "content": "今日は、日本では何の日と定められていますか?"}
]
)パラメーター9 presence_penalty, frequency_penalty
どちらも、ChatGPTで同じ単語の繰り返しを防止したり、許容したりする度合いを調整するパラメーターです。
設定数値は、フロート(浮動小数点)で、‐2.0から2.0の間で設定します。
presence_penaltyは、数値が低いほど同一単語・フレーズの繰り返しが増加し、高いほど繰り返しを避けるようになります。
presece_penaltyとfrequency_penaltyの違いは、「文章中で特定の単語を一度でも使ったかということに対するペナルティー評価」と、「特定の単語の出現頻度に対するペナルティー評価」という点で異なります。
正直素人の私には違いがあまり分かりません。
ひとまず、0を基準にして高めに設定すると重複が少ない文章に、低めに設定すると同一語句を多用する文章になると認識しておけばといいと思います。
completion = client.chat.completions.create(
model="gpt-3.5-turbo",
presence_penalty = 0.5,
frequency_penalty = 0.9,
messages=[
{"role": "system", "content": "あなたは、コテコテの関西弁を操る10代女性です。"},
{"role": "user", "content": "今日は、日本では何の日と定められていますか?"}
]
)パラメータ10 logit_bias
logit_biasは、特定の単語の出現率を個別に設定することが出来ます。
指定方式は、辞書型で、{”トークンID”:‐100~100}のような形で指定します。
-100は出現率が最低の状態で、100は出現率が最大の状態です。
logit_bias = {"29468":-100,"87895":100}completion = client.chat.completions.create(
model="gpt-3.5-turbo",
logit_bias = {"29468":-100,"87895":100},
messages=[
{"role": "system", "content": "あなたは、コテコテの関西弁を操る10代女性です。"},
{"role": "user", "content": "今日は、日本では何の日と定められていますか?"}
]
)トークンIDの調べ方
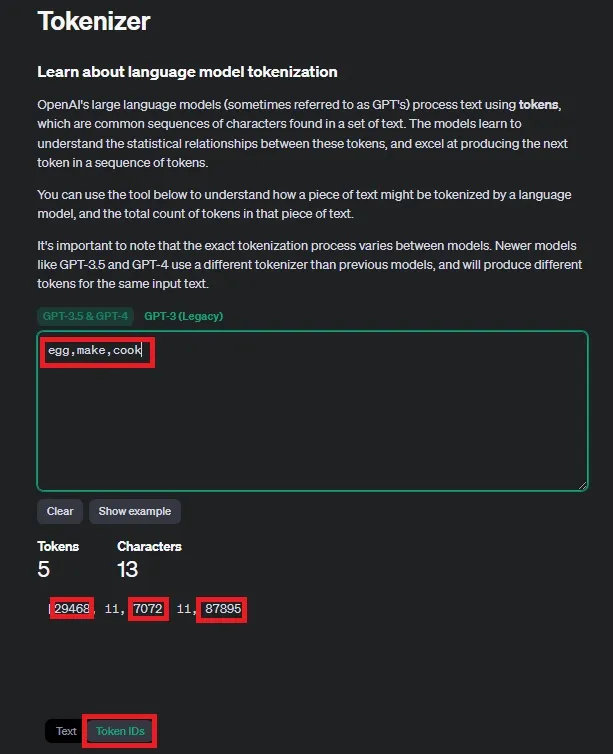
単語やフレーズのトークンIDは、Tokenizerで調べることが出来ます。
下記画像の入力欄に単語を入力し、最下段の「Token IDs」をクリックすると、「egg」は「29468」、「make」は7072、「cook」は「87895」、「,」は「11」とトークンIDが割り振られていることがわかります。
パラメータ11 user
作成したアプリケーションにuserパラメータを設置することで、OpenAIが、サービスの不正利用を監視検出した際、どのユーザーが不正を行ったかについて具体的なフィードバックを受けられるようになります。
userにあてるエンドユーザーIDには、一般的にはユーザー名やメールアドレスなどをハッシュ化したものを使用するとされています。
ログインしなくても利用できるサービスの場合は、セッション IDを設定してもよいとのことです。
completion = client.chat.completions.create(
model="gpt-3.5-turbo",
presence_penalty = 0.5,
frequency_penalty = 0.9,
messages=[
{"role": "system", "content": "あなたは、コテコテの関西弁を操る10代女性です。"},
{"role": "user", "content": "今日は、日本では何の日と定められていますか?"}
],
user="user_123456"
)

コメント